I Tried Out Gemini’s New Native Image Gen Feature, and It’s Fricking Nuts

We have been hearing the term ‘natively multimodal‘ in the AI space for over a year, but companies were slow in unlocking full multimodal capabilities of their AI models until now. Google has finally released its latest “Gemini 2.0 Flash Experimental” model with the ability to generate and edit images natively.
Now, you might be wondering, what is the big deal with image generation? AI image generation has been available with all major AI chatbots like ChatGPT for quite some time. Well, when we generate AI images on ChatGPT or Gemini, the prompt is routed to a specialized Diffusion-based model like Dall-E 3 or Imagen 3. The said models are trained on images and designed only to generate images; they are like an extension to the main AI model and not part of it.
However, language-vision models like Gemini are natively multimodal, meaning they can inherently understand, generate, and modify both text and images. Until now, no tech company had made this capability available to users. OpenAI demonstrated its native image generation feature with GPT-4o in 2024, but again, it was never released.
With native image generation, you get better consistency as multimodal models are trained on a large dataset of different modalities. As a result, such models boast better understanding of concepts and exhibit broader world knowledge.
Beyond image generation, you can seamlessly edit images with simple prompts. For example, you can upload an image and ask the model to add sunglasses, insert legible text, remove objects, and more to the image. And unlike Diffusion models which regenerate the whole image with each new prompt, natively multimodal models maintain consistency across multiple modifications.
Native Image Generation with Gemini 2.0 Flash Experimental
Currently, the native image generation feature is not available to general users. The Gemini 2.0 Flash Experimental model with native image generation is only available on Google’s AI Studio (visit) for free.
After previewing the model on AI Studio, it will be released on Gemini for everyone to use in the near future. However, I tried out the new Gemini model with native image generation, and it was quite the exciting experience.
First, I started with a visual guide to showcase the consistency of Gemini’s native image generation capability. I asked Gemini to create a visual guide on how to make an omelet, generating an image for each step of the process.
As you can notice, the results are highly consistent across images with no glitches. Even the bowl is the same in the second image. Finally, you can download the images in 1024 x 680 resolution. This way, you can create a visual guide on anything you want.
Next, I asked Gemini to create an aesthetic table and then told it to show the table from the center camera angle. It did a perfect job. After that, I prompted Gemini to add a PlayStation to the table and give me a closer look. Again, Gemini nailed it. The AI model, as you see below, also included a reflection of the PS5 in the mirror behind it.
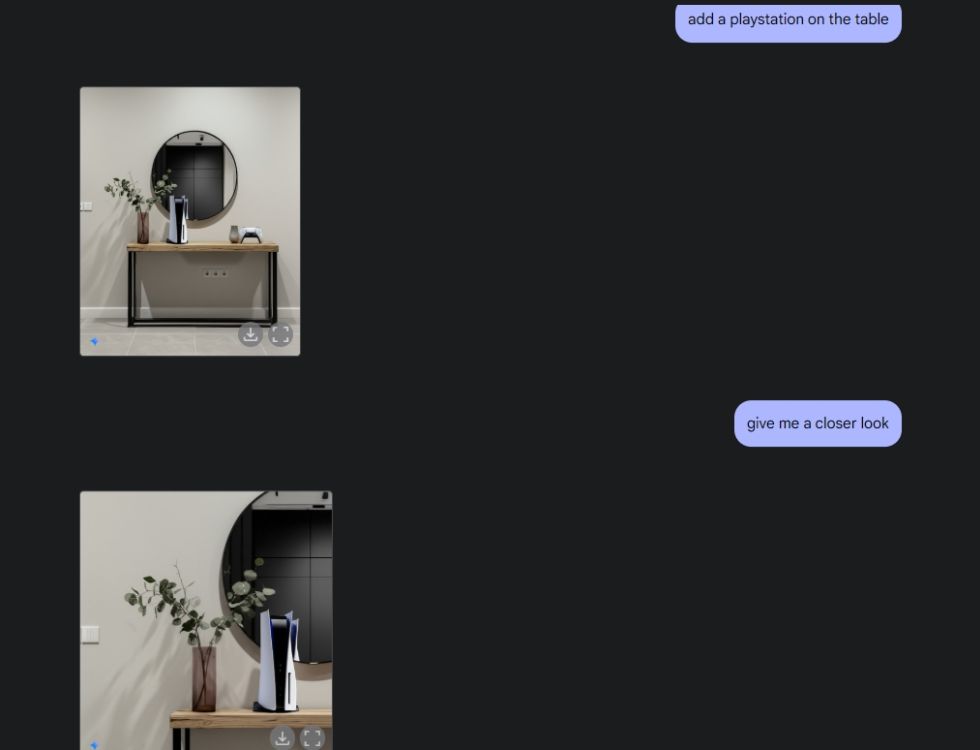
Native Image Editing with Gemini 2.0 Flash Experimental
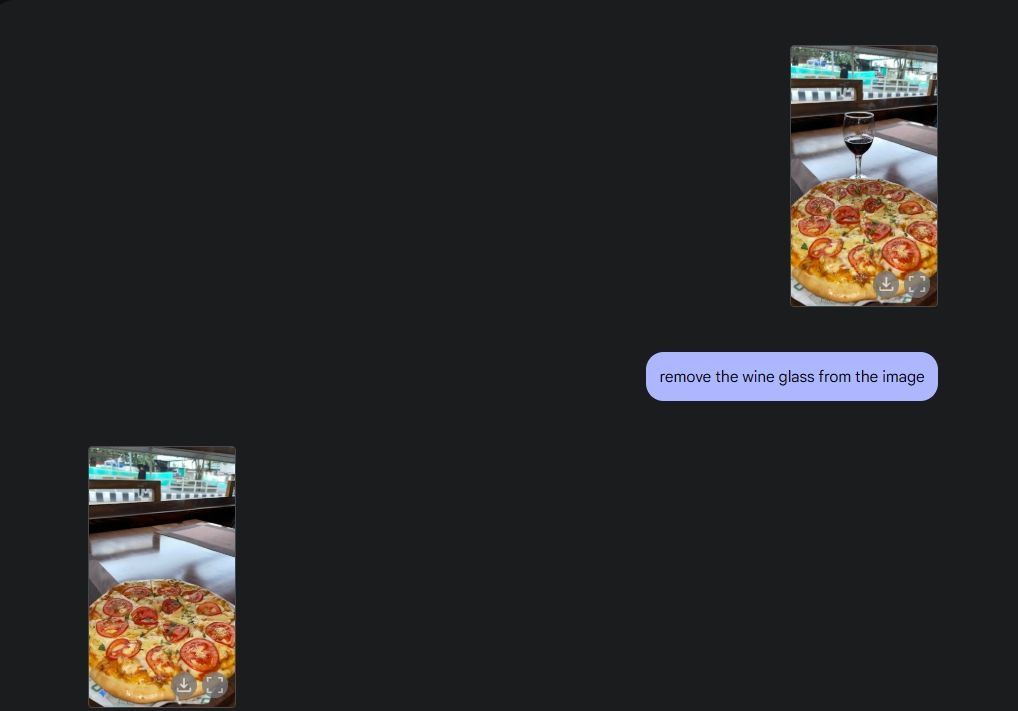
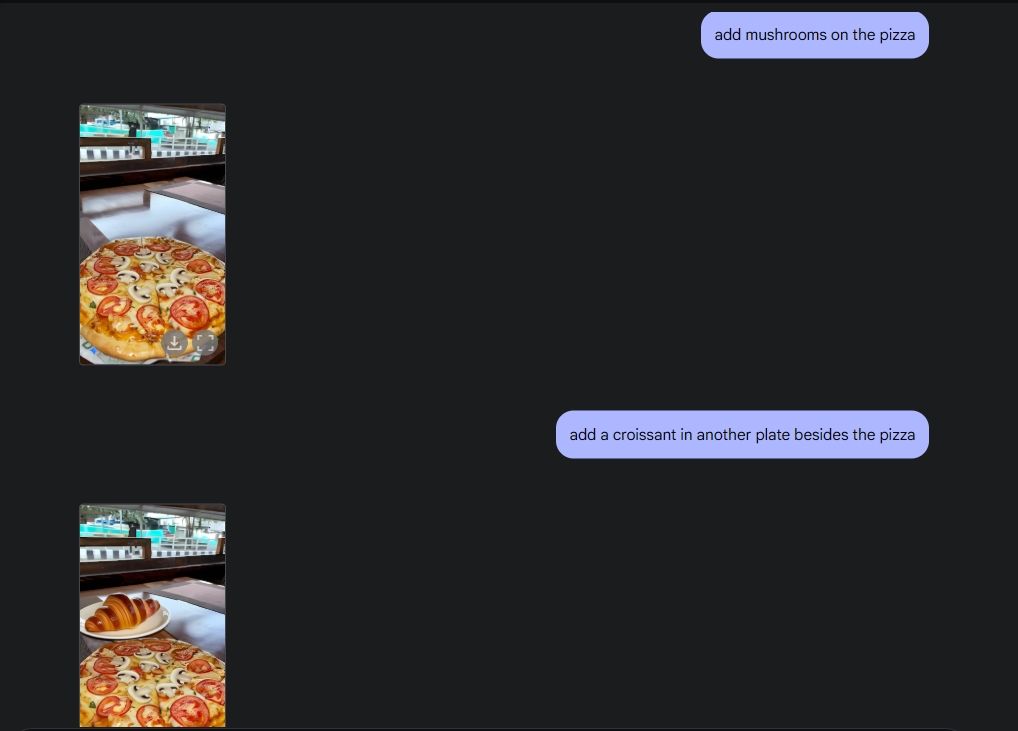
To demonstrate native image editing, I uploaded an image from my gallery and asked Gemini 2.0 to remove the wine glass from the table. Following that, I told Gemini to add mushrooms to the pizza, and it did a wonderful job. Then, I prompted Gemini to add a croissant and there you have AI image editing in full glory, thanks to Gemini’s native multimodal capability.
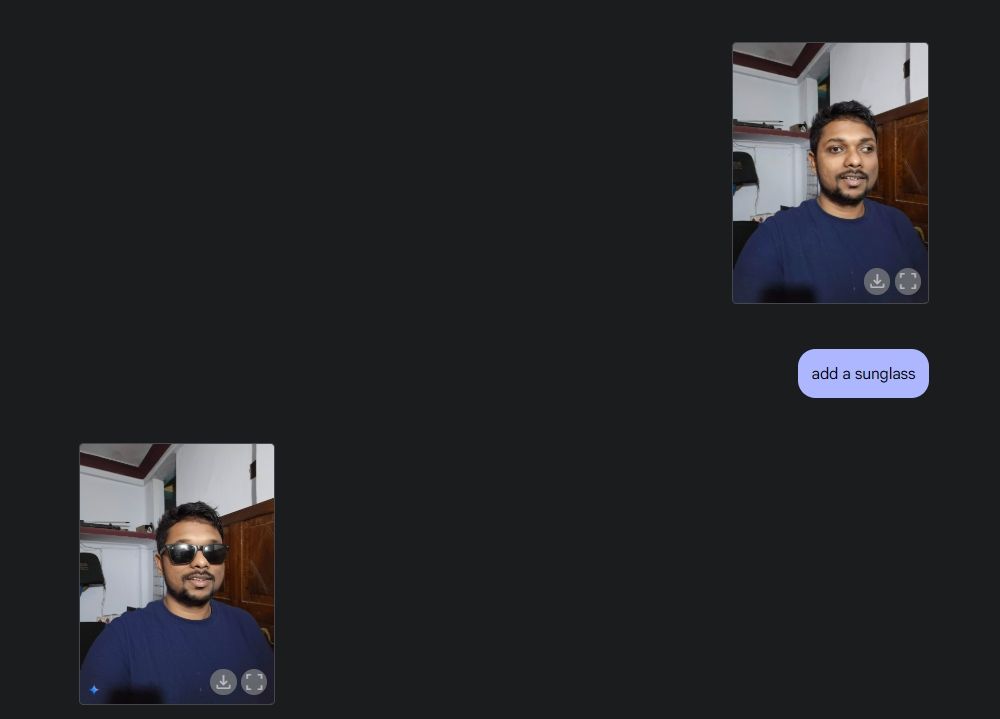
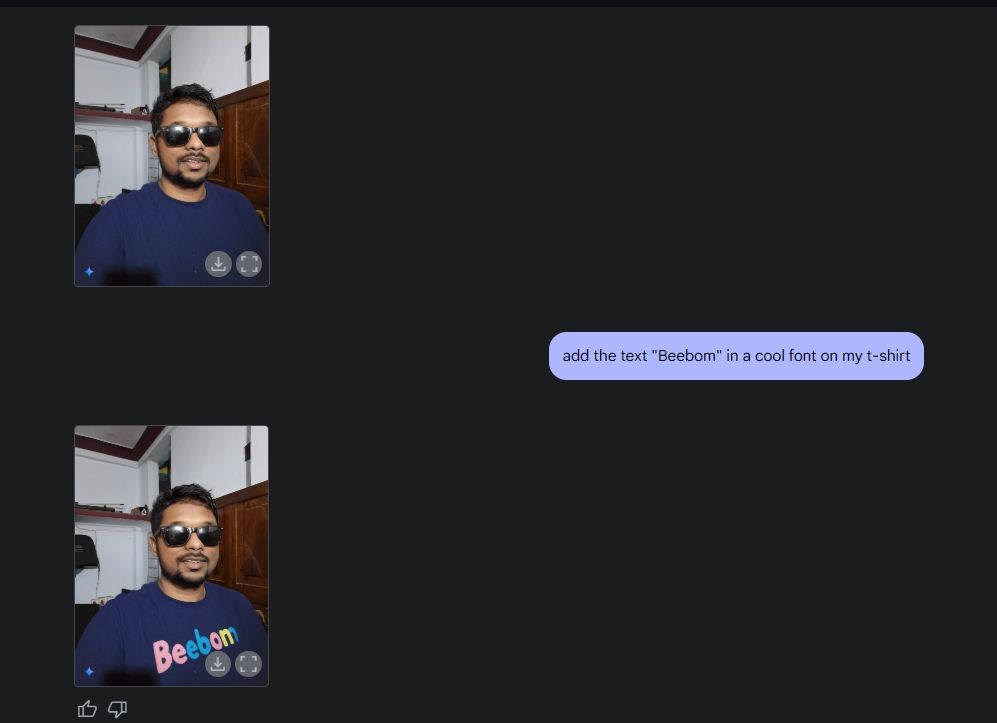
Next, I uploaded an image of mine, and asked Gemini to add sunglasses and then add the “Beebom” text on my t-shirt. Both were done quite well.
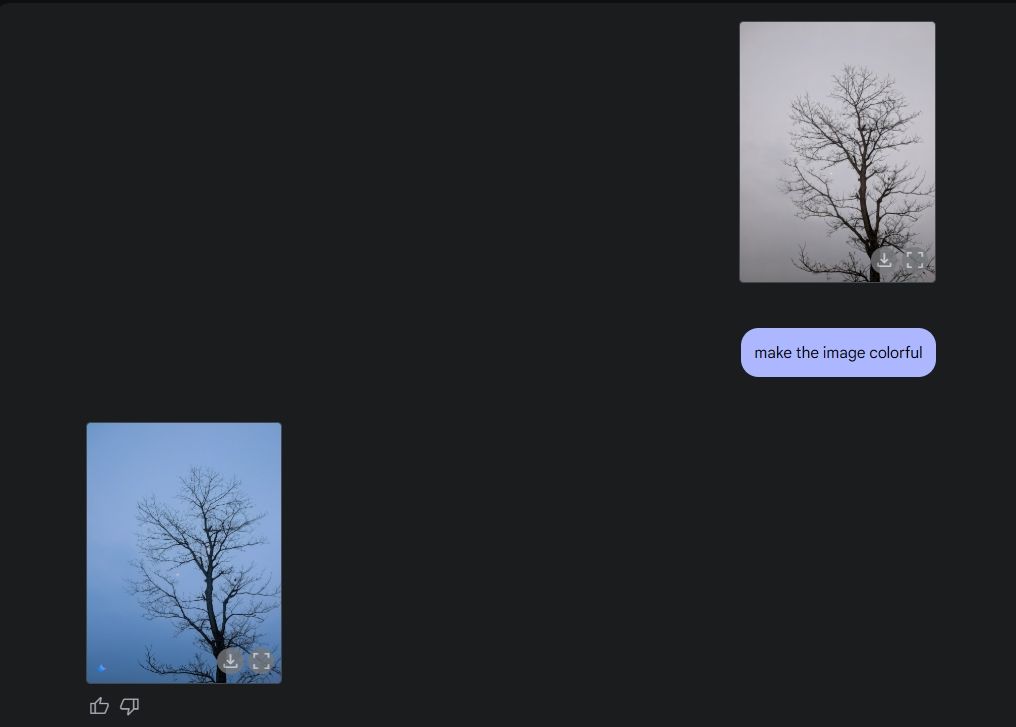
Lastly, I asked Gemini to colorize an image, and it worked really well too. I mean, the image came out more beautiful than it was before, without any weird glitches, artifacting, or part of the image missing.
There are many such use cases that you can try with Gemini’s new multimodal capability. Google has done a commendable job with native image generation and editing, and I’m planning to use it more rigorously in the coming weeks to test its limits.
After the release of Veo 2 for video generation and Imagen 3 for specialized image generation, it appears Google has outclassed OpenAI in many areas; not just AI text generation. So, it would be interesting to see what OpenAI does next to reclaim the top spot with ChatGPT.
Source link








