Nvidia Competitors: AI Chipmakers Fighting the Silicon War

Nvidia joined the 3-trillion market valuation club in June earlier this year, outranking the likes of Apple and Minecraft. This astronomical growth has been possible due to its dominance in the GPU and AI hardware space. However, Nvidia is not the only company making chips for today’s growing AI workloads. Many companies, such as Intel, Google, Amazon, and others, are working on custom silicon for training and inferencing AI models. So, let’s look at promising Nvidia competitors in the AI hardware space.
AMD
When it comes to high-performing AI accelerators, AMD is up there competing against Nvidia, both in terms of training and inference. While analysts suggest that Nvidia has a market share of 70% to 90% in the AI hardware space, AMD has started putting its house in order.
AMD introduced its Instinct MI300X accelerator for AI workloads and HPC (High Performance Computing) in December 2023. AMD claims that its Instinct MI300X accelerator delivers 1.6x better performance than Nvidia H100 in inference and almost similar performance in training.
Not only that, it offers a capacity of up to 192GB HBM3 memory (High-Bandwidth Memory), much higher than Nvidia H100’s 80GB capacity. MI300X delivers a memory bandwidth of up to 5.3 TBps, again higher than H100’s 3.4 TBps.
So AMD is really putting up a fight against Nvidia’s reign. However, AMD still has a long way to go before it establishes itself as a major rival to Nvidia. The answer to this lies in software. Nvidia’s moat is CUDA, the computing platform that allows developers to directly interact with Nvidia GPUs for accelerated parallel processing.
The CUDA platform has a large number of libraries, SDKs, toolkits, compilers, and debugging tools, and it’s supported by popular deep learning frameworks such as PyTorch and TensorFlow. On top of that, CUDA has been around for nearly two decades, and developers are more familiar with Nvidia GPUs and their workings, especially in the field of machine learning. Nvidia has created a large community around CUDA with better documentation and training resources.
That said, AMD is investing heavily in the ROCm (Radeon Open Compute) software platform and it supports PyTorch, TensorFlow, and other open frameworks. The company has also decided to open-source some portion of the ROCm software stack. However, developers have criticized ROCm for offering a fragmented experience and a lack of comprehensive documentation. Remember George Hotz calling out AMD for its unstable driver?
So the bottom line is that AMD must unify its software platform and bring ML researchers and developers into its fold with better ROCm documentation and support. Big giants like Microsoft, Meta, OpenAI, and Databricks are already deploying MI300X accelerators under ROCm so that’s a good sign.
Intel
Many analysts are writing off Intel from the AI chip space, but Intel has been one of the leaders in inferencing with its CPU-based Xeon servers. The company recently launched its Gaudi 3 AI accelerator, which is an ASIC (Application-Specific Integrated Circuit) chip that is not based on traditional CPU or GPU design. It offers both training and inference for Generative AI workloads.

Intel claims the Gaudi 3 AI accelerator is 1.5x faster at training and inference than Nvidia H100. Its Tensor Processor Cores (TPC) and MME Engines are specialized for matrix operations which are required for deep learning workloads.
As for software, Intel is going the open-source route with OpenVINO and its own software stack. The Gaudi software suite integrates frameworks, tools, drivers, and libraries and supports open frameworks like PyTorch and TensorFlow. In regards to Nvidia’s CUDA, Intel chief, Pat Gelsinger recently said:
You know, the entire industry is motivated to eliminate the CUDA market. We think of the CUDA moat as shallow and small.
In case you are not aware, Intel along with Google, Arm, Qualcomm, Samsung, and other companies have formed a group called the Unified Acceleration Foundation (UXL). The group aims to create an open-source alternative to Nvidia’s proprietary CUDA software platform. The task is to create a silicon-agnostic platform to train and run models on any chip. This will prevent developers from getting locked into Nvidia’s CUDA platform.
Now, what shape the future will take is something only time will tell. But Intel’s effort to dethrone CUDA has started.
Related Articles
In Today’s AI Race, Don’t Gamble with Your Digital Privacy
May 1, 2024
If there is an AI giant that is not reliant on Nvidia, it’s Google. Yes, you read that right. Google has been developing its in-house TPU (Tensor Processing Unit) since 2015 on ASIC design. Its powerful TPU v5p is 2.8x faster than Nvidia H100 at training AI models and highly efficient at inference. And the sixth-gen Trillium TPU is even more powerful. Google uses its TPU for training, finetuning, and inferencing.
At the Google Cloud Next 2024 event, Patrick Moorhead, Founder and CEO at Moor Insights & Strategy. got confirmation from Google that its Gemini model was trained entirely on the TPU, which is pretty significant. It’s already used for inferencing on Gemini.
The search giant offers its TPU through Google Cloud for a variety of AI workloads. In fact, Apple’s AI models were trained on Google’s TPU. In that sense, Google is a true rival to Nvidia, and with its custom silicon, it beats other chip makers both in training and inferencing.
Unlike Microsoft, Google is not over-reliant on Nvidia. Not to forget, Google recently introduced its Axion processor which is an Arm-based CPU. It delivers unrivaled efficiency for data centers and can handle CPU-based AI training and inferencing as well.
Finally, in software support as well, Google has the upper hand. It supports frameworks like JAX, Keras, PyTorch, and TensorFlow out of the box.
Amazon
Amazon runs AWS (Amazon Web Services) which offers cloud-computing platforms for businesses and enterprises. To cater to companies for AI workloads, Amazon has developed two custom ASIC chips for training and inferencing. AWS Trainium can handle deep-learning training for up to 100B models. And AWS Inferentia is used for AI inferencing.

The whole point of AWS custom chips is to offer low cost and high performance. Amazon is internally scaling its effort to stake a claim in the AI hardware space. The company also has its own AWS Neuron SDK, integrating popular frameworks like PyTorch and TensorFlow.
Microsoft
Similar to Google, Microsoft is also ramping up its custom silicon effort inside the company. In November 2023, Microsoft introduced its MAIA 100 chip for AI workloads and Cobalt 100 (Arm-based CPU) for its Azure cloud infrastructure. The Redmond giant is trying to avoid a costly over-reliance on Nvidia for its AI computing needs.

The MAIA 100 chip is developed on an ASIC design, used specifically for AI inferencing and training. Reportedly, the MAIA 100 chip is currently being tested for GPT-3.5 Turbo inferencing. Microsoft has a deep partnership with Nvidia and AMD for its cloud infrastructure needs.
So, we don’t know how the relationship will pan out once Microsoft and other companies start deploying their custom silicon widely.
Qualcomm
Qualcomm released its Cloud AI 100 accelerator in 2020 for AI inferencing, but it hasn’t taken off, as expected. The company refreshed it with Cloud AI 100 Ultra in November 2023. The chipmaker claims the Cloud AI 100 Ultra is custom-built (ASIC) for generative AI applications. It can handle 100B parameter models on a single card with a TDP of just 150W.

Qualcomm has developed its own AI stack and cloud AI SDK. The company is mainly interested in inferencing rather than training. The whole promise of Qualcomm Cloud AI 100 Ultra is its unparalleled power efficiency. It offers up to 870 TOPS while performing INT8 operations.
Hewlett Packard Enterprise (HPE) is using the Qualcomm Cloud AI 100 Ultra to power generative AI workloads on its servers. And Qualcomm has partnered with Cerebras to provide end-to-end model training and inferencing on a single platform.
Related Articles
Apple M4 vs Snapdragon X Elite: Can Qualcomm Keep Up?
May 8, 2024
Cerebras
Apart from the bigwigs out there, Cerebras is a startup working on training large-scale AI systems. Their Wafer-Scale Engine 3 (WSE-3) is actually a large wafer-scale processor that can handle models up to 24 trillion parameters, 10 times the size of GPT-4. That’s an insane number.

It features a whopping 4 trillion transistors because it’s a giant chip that uses nearly all of the wafer. No need to interconnect multiple chips and memory. It also helps in reducing power as there is less data movement between various components. It beats Nvidia’s state-of-the-art Blackwell GPUs in terms of petaflops per watt.
The Cerebras WSE-3 chip is targeted at mega-corporations that want to build large and highly powerful AI systems by eliminating distributed computing. Cerebras has bagged customers such as AstraZeneca, GSK, The Mayo Clinic, and major US financial institutions.
Moreover, the company recently launched its API for Cerebras Inference, which offers unparalleled performance on Llama 3.1 8B and 70B models.
Groq
Also, Groq took the AI industry by storm earlier this year with its LPU (Language Processing Unit) accelerator. It consistently generates 300 to 400 tokens per second while running the Llama 3 70B model. After Cerebras, it’s the second fastest AI inferencing solution that can actually be used by developers in their production apps and services.
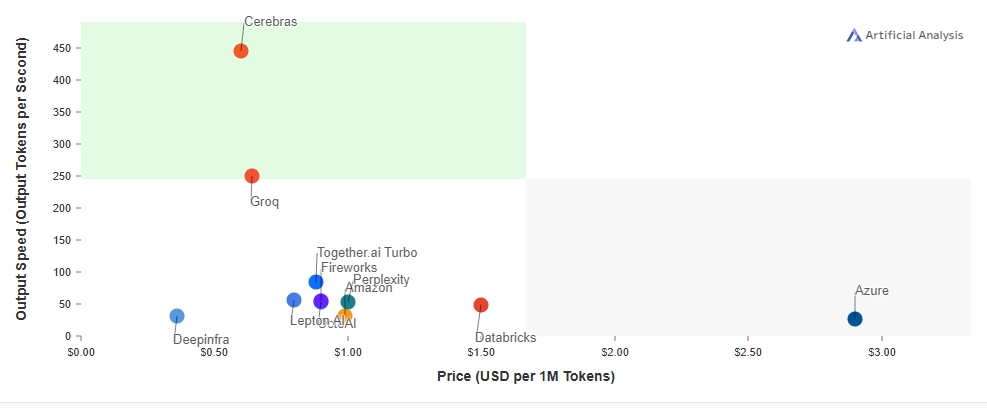
Groq is an ASIC chip, purpose-built for generative AI applications by ex-Google TPU engineers. It unlocks parallelism at a massive scale. And in terms of cost, it’s cheaper to run AI models on Groq’s LPU than on Nvidia GPUs. While for relatively smaller models, Groq’s LPU runs fine. We need to see how it performs when running 500B+ or trillion-scale models.
Closing Thoughts
These are the chipmakers other than Nvidia competing in the AI hardware space. SambaNova is also offering training-as-a-service, but we have not seen any quantifiable benchmarks of the AI accelerator to make a judgment. Other than that, Tenstorrent is now moving to RISC-V based IP licensing for its chip designs.
Overall, the AI industry is moving towards custom silicon and developing in-house purpose-built AI accelerators. While for training, Nvidia is still the preferred choice due to CUDA’s wide adoption, in the coming years, the trend may shift as more specialized accelerators mature. For inference, there are already many solutions outperforming Nvidia at this moment.
The AI landscape on the software front is changing rapidly. Now, it’s time for AI accelerators to mark a paradigm shift.