Discrepancy
-
Blog
AI Benchmark Discrepancy Reveals Gaps in Performance Claims
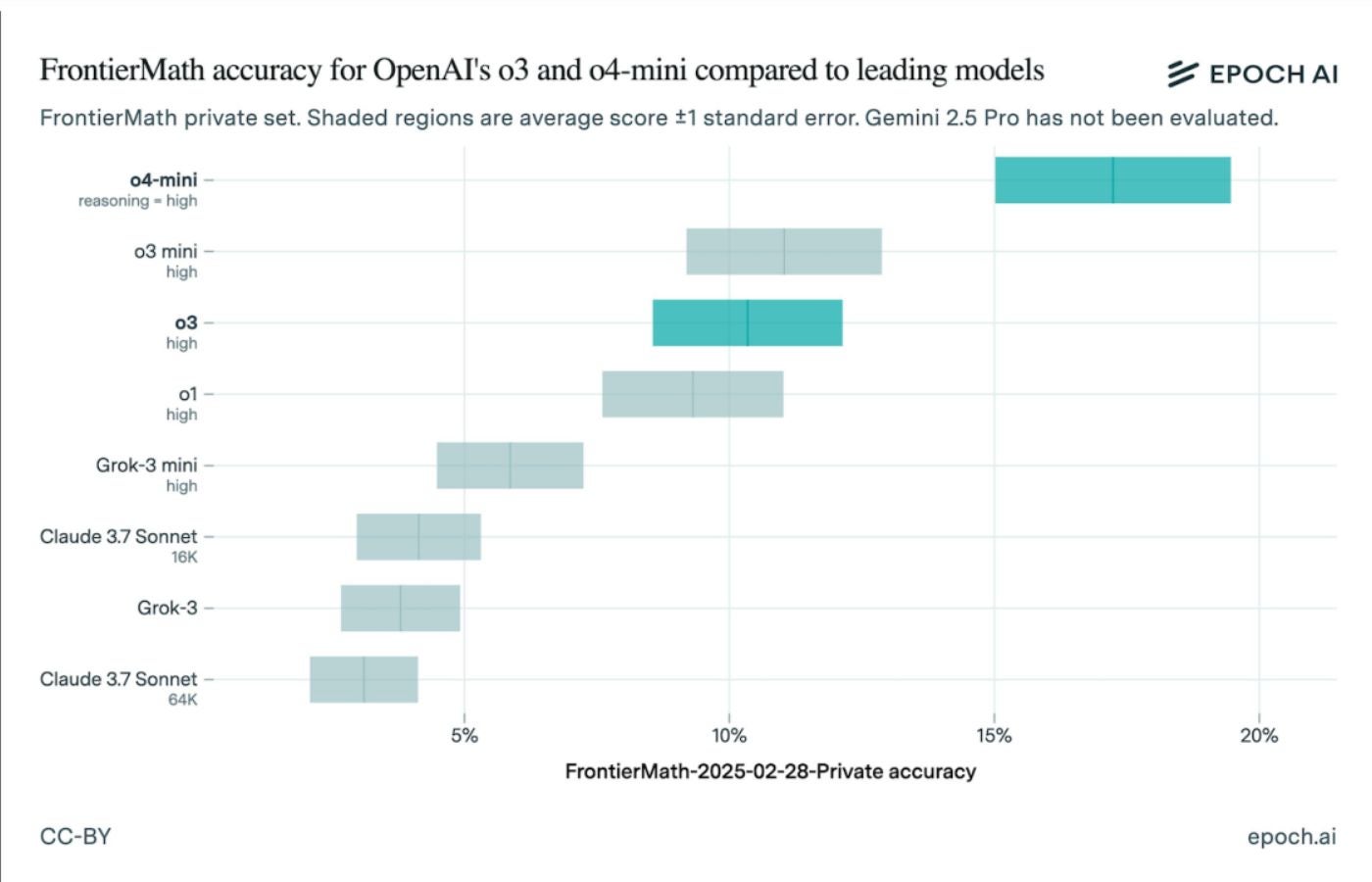
FrontierMath accuracy for OpenAI’s o3 and o4-mini compared to leading models. Image: Epoch AI The latest results from FrontierMath, a benchmark test for generative AI on advanced math problems, show OpenAI’s o3 model performed worse than OpenAI originally stated. While newer OpenAI models now outperform o3, the discrepancy highlights the need to scrutinize AI benchmarks closely. Epoch AI, the research…
Read More »