In an evolving health landscape, emerging research continues to highlight concerns that could impact everyday wellbeing. Here’s the key update you should know about:
By reading subtle throat vibrations and pulse signals, a lightweight AI-powered choker helps stroke survivors communicate more smoothly, transforming brief, effortful inputs into clearer, emotionally tuned speech.
Study: Wearable intelligent throat enables natural speech in stroke patients with dysarthria. Image credit: Hamara/Shutterstock.com
A recent study in Nature Communications evaluated a newly developed wearable artificial intelligence (AI)-driven intelligent throat (IT) system that integrated throat muscle vibration and carotid pulse signal sensors with a large language model (LLM) processing to enable more continuous communication and, optionally, expanded, emotionally aligned sentences in controlled experimental settings.
Addressing Communication Challenges in Neurological Disease Patients
Neurological diseases, including stroke, amyotrophic lateral sclerosis (ALS), and Parkinson’s disease, often cause dysarthria, which is a debilitating motor-speech disorder that disrupts neuromuscular control of the vocal tract. Patients with dysarthria experience significant barriers to effective communication, which affects quality of life, hinders rehabilitation, and increases psychological distress.
Researchers have developed augmentative and alternative communication (AAC) technologies, such as letter-by-letter spelling systems using head or eye tracking and brain-computer interface (BCI)-powered neuroprosthetics. Even though head and eye-tracking systems are relatively simple to deploy, they operate at significantly slow speeds.
Neuroprosthetics show great promise for severely paralyzed patients but require invasive procedures and complex neural signal processing. For patients who still have some control over their throat or facial muscles, simpler and more portable communication solutions are needed.
Wearable silent-speech devices that capture non-acoustic signals offer a promising, non-invasive solution. However, current systems have certain limitations that stem from the fact that they are tested mainly on healthy participants, require word-level decoding that disrupts communication flow, and use 1:1 mapping that strains fatigued patients. Systems that expand shorter expressions into coherent sentences on demand are essential for natural communication.
An AI-powered wearable silent speech system for dysarthria patients
The current study developed an AI-driven IT system to advance wearable silent speech technology for dysarthria patients. The system captures laryngeal muscle vibrations and carotid pulse signals, integrating real-time analysis of silent speech and emotional state to generate either direct text output or expanded, contextually appropriate sentences that reflect patients’ intended meaning during everyday-style communication tasks.
The IT system consists of a smart choker with textile strain sensors and a wireless circuit board, along with machine learning models and large language model agents. Using ultrasensitive textile strain sensors fabricated through advanced printing techniques, the device ensures comfortable, durable, and high-quality signal acquisition.
Silent speech signals were decoded by a token-decoding network and synthesized into sentences by the token-synthesis agent. LLMs functioned as intelligent agents, automatically correcting token classification errors and generating personalized, context-aware speech by incorporating emotional states and objective contextual information such as time of day and weather, retrieved via a local software interface.
Along with silent speech signals, pulse signals were processed by an emotion-decoding network to determine emotional state. Emotional labels were limited to three experimentally elicited categories: neutral, relieved, and frustrated. The sentence expansion agent expanded the generated sentence by incorporating emotion labels and contextual data when the user activated it, producing refined, emotionally aligned output.
The circuit board enables bi-channel measurements of silent speech and pulse signals for simultaneous acquisition of speech and emotional cues. It integrates a low-power Bluetooth module, analog-to-digital converter, and microcontroller for data processing and transmission. The board consumes 76.5 mW of total power, with a 1,800 mWh battery providing all-day operation.
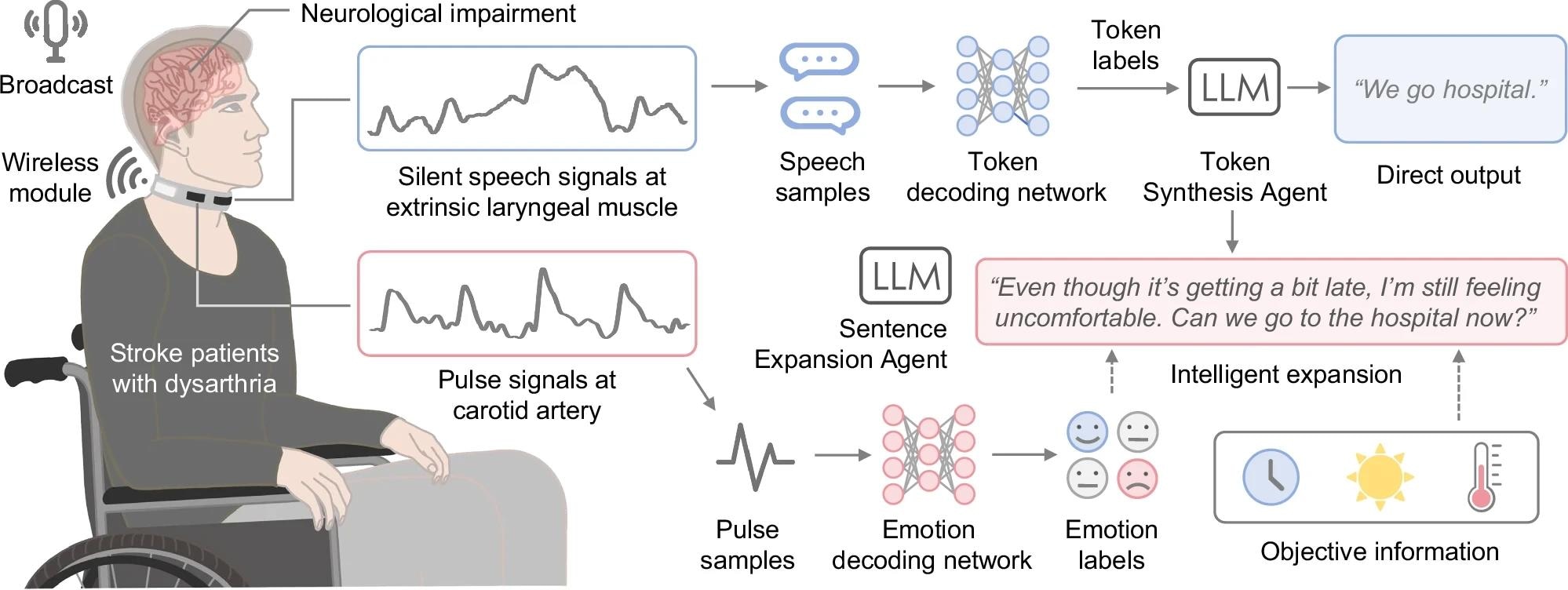 The system captures extrinsic laryngeal muscle vibrations and carotid pulse signals via textile strain sensors and transmits them to the server through a wireless module.
The system captures extrinsic laryngeal muscle vibrations and carotid pulse signals via textile strain sensors and transmits them to the server through a wireless module.
Training the wearable IT system
The study included 10 healthy subjects (age, 25.3 years, 6 males, 4 females) and 5 stroke patients with dysarthria (age, 43 years, 4 males, 1 female). A corpus of 47 Chinese words and 20 sentences was developed based on the common daily communication needs of stroke patients. These sentences were randomly selected from therapist-curated rehabilitation materials.
Healthy subjects completed 100 repetitions per word and 50 per sentence, while patients completed 50 repetitions per word and 50 per sentence. Carotid pulse signals were recorded synchronously with silent speech signals for the patient group only. Data were excluded only when sensor connections failed; all other signals, including those with motion artifacts or noise, were retained to improve model generalizability.
The device was resistant to external sound interference, maintaining an unchanged signal response even under 100 dB of noise. Participants performed silent mouthing without vocalization. Silent speech signals were recorded at 10 kHz, downsampled to 1 kHz, and segmented into 144 ms tokens. Each token was combined with the preceding 14 tokens to incorporate context, then detrended and z-score normalized.
Healthy subject data provided a baseline for initial model training, establishing foundational patterns before fine-tuning on dysarthric patient data.
Assessing the IT system’s performance
The IT system analyzed speech signals at the token level, approximately 100 milliseconds, outperforming traditional time-window methods and enabling continuous expression in near real time with end-to-end response on the order of seconds when speech synthesis was included.
Knowledge distillation reduced computational load and corresponding latency by approximately 76 %, while maintaining 91.3 % accuracy. The model achieved an average per-word accuracy of 96.3 % across five visually and articulatorily similar word pairs, reliably distinguishing between look-alike mouth shapes. Over 90 % of classification errors involved confusion between blank tokens and neighboring word tokens, which were corrected during token-to-word synthesis.
For emotion recognition, patients’ pulse signals were segmented into 5-second windows for three emotion categories: neutral, relieved, and frustrated. Discrete Fourier transform frequency extraction was incorporated into the decoding pipeline. To prevent crosstalk from silent speech vibrations propagating into the carotid artery, a stress-isolation treatment using a polyurethane acrylate layer was employed, improving the signal-to-interference ratio by more than 20 dB.
Overall, the system achieved a 4.2 % word error rate and a 2.9 % sentence error rate under optimized synthesis conditions, along with 83.2 % emotion recognition accuracy. Patient satisfaction increased by 55 % when using the sentence expansion mode compared with direct output, suggesting that even brief, effort-efficient inputs could be transformed into fuller, socially usable expressions.
Intelligent throat shows promise for naturalistic communication
The IT system offered a comprehensive solution for dysarthria patients, enabling more natural communication through token-based decoding, emotion recognition, and user-selectable intelligent sentence expansion. While evaluated in a small cohort with a defined vocabulary, the system demonstrated potential to reduce social isolation and support rehabilitation by lowering the physical and cognitive effort required to communicate.
Future research will focus on expanding the system to larger patient cohorts, broader vocabularies, and diverse neurological conditions.
Journal reference:
-
Tang, C., Gao, S., Li, C., Yi, W., Jin, Y., Zhai, X., Lei, S., Meng, H., Zhang, Z., Xu, M., Wang, S., Chen, X., Wang, C., Yang, H., Wang, N., Wang, W., Cao, J., Feng, X., Smielewski, P., . . . Occhipinti, L. G. (2026). Wearable intelligent throat enables natural speech in stroke patients with dysarthria. Nature Communications, 17(1), 293. DOI: https://doi.org/10.1038/s41467-025-68228-9. https://www.nature.com/articles/s41467-025-68228-9