In an evolving health landscape, emerging research continues to highlight concerns that could impact everyday wellbeing. Here’s the key update you should know about:
More than 64,000 proteomics datasets have now flowed through ProteomeXchange, and the consortium’s latest update shows how smarter standards, stronger reuse tools, and AI-ready resources are reshaping biological data sharing.
Database Update: The ProteomeXchange consortium in 2026: making proteomics data FAIR. Image Credit: Christoph Burgstedt /Shutterstock
In a recent database update paper published in the journal Nucleic Acids Research, an international team of authors described recent advancements, data growth, standardization, and future directions of the ProteomeXchange Consortium in enabling FAIR (Findable, Accessible, Interoperable, Reusable) proteomics data sharing.
Proteomics Data Sharing Background and FAIR Principles
What happens when thousands of biological datasets remain unused? In proteomics, data sharing is essential to advance research on diseases, drugs, and human biology. Over the past decade, the rapid rise of mass spectrometry-based proteomics has generated vast datasets, yet their value depends on accessibility and reuse. The FAIR principles were developed to guide scientific data management and stewardship in ways that support reproducible and transparent science. Collaborative platforms now play a crucial role in integrating and distributing such data across disciplines. However, continuous innovation is needed to handle the growing complexity of new datasets.
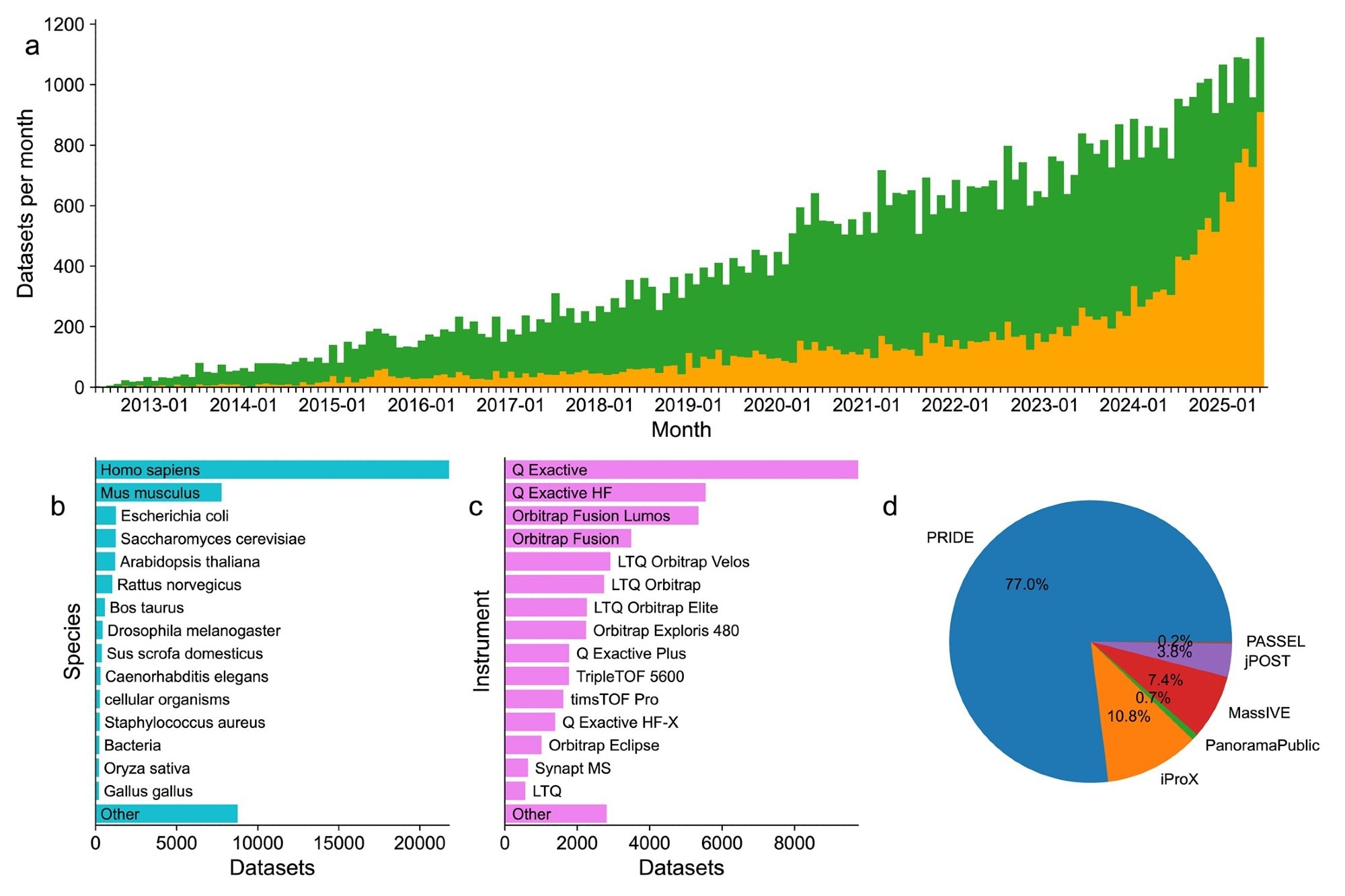
Summary statistics for datasets deposited to ProteomeXchange resources since 2012. (A) Trend in publicly released (green) and not-yet released (orange) datasets from May 2012 through June 2025. A total of 1156 datasets were submitted in June 2025. (B) Summary of the top 15 species for publicly released datasets since 2012. (C) Summary of the top 15 instruments as reported by submitters for publicly released datasets since 2012. (D) Summary of the relative number of all datasets by the receiving repository.
ProteomeXchange Infrastructure and Data Standards
The consortium maintains an infrastructure that allows for the standardized submission, storage, and dissemination of proteomic data generated by mass spectrometry. Member repositories that contributed to data archiving and access include PRoteomics IDEntifications database (PRIDE), PeptideAtlas, Mass Spectrometry Interactive Virtual Environment (MassIVE), Japan Proteome Standard Repository/Database (jPOST), Integrated Proteome Resources (iProX), and Panorama Public. Datasets submitted consisted of raw mass spectrometry files, processed data with identification and quantification results, and experimental metadata structured according to Proteomics Standards Initiative (PSI)-developed standards.
Efficient uploads were conducted using a number of data transfer protocols, including File Transfer Protocol (FTP), Aspera, Hypertext Transfer Protocol Secure (HTTPS), Web Distributed Authoring and Versioning (WebDAV), and PRESTO. Additionally, standardization of metadata was improved through the Sample and Data Relationship Format (SDRF)-Proteomics, enabling clear mapping between samples and experimental conditions. Unique dataset identifiers (ProteomeXchange dataset identifiers) ensured traceability, while reanalyzed datasets were assigned RPXD identifiers.
ProteomeCentral integrated metadata from all repositories, enabling search and retrieval of datasets through a single platform. Universal Spectrum Identifiers (USIs) allowed for accurate identification and visualization of single spectra. The infrastructure also facilitated their reuse at scale, integration with external resources, and use in machine learning and artificial intelligence (AI) workflows.
ProteomeXchange Growth, Reuse, and AI Applications
Updated submission statistics from the consortium showed substantial growth in global proteomics data sharing and reuse. By June 2025, a total of 64,330 datasets had been submitted, with 44,248 (69%) publicly accessible, reflecting a strong commitment to open science. Notably, 47% of all datasets were submitted within the last three years, highlighting an accelerating trend in data generation and sharing.
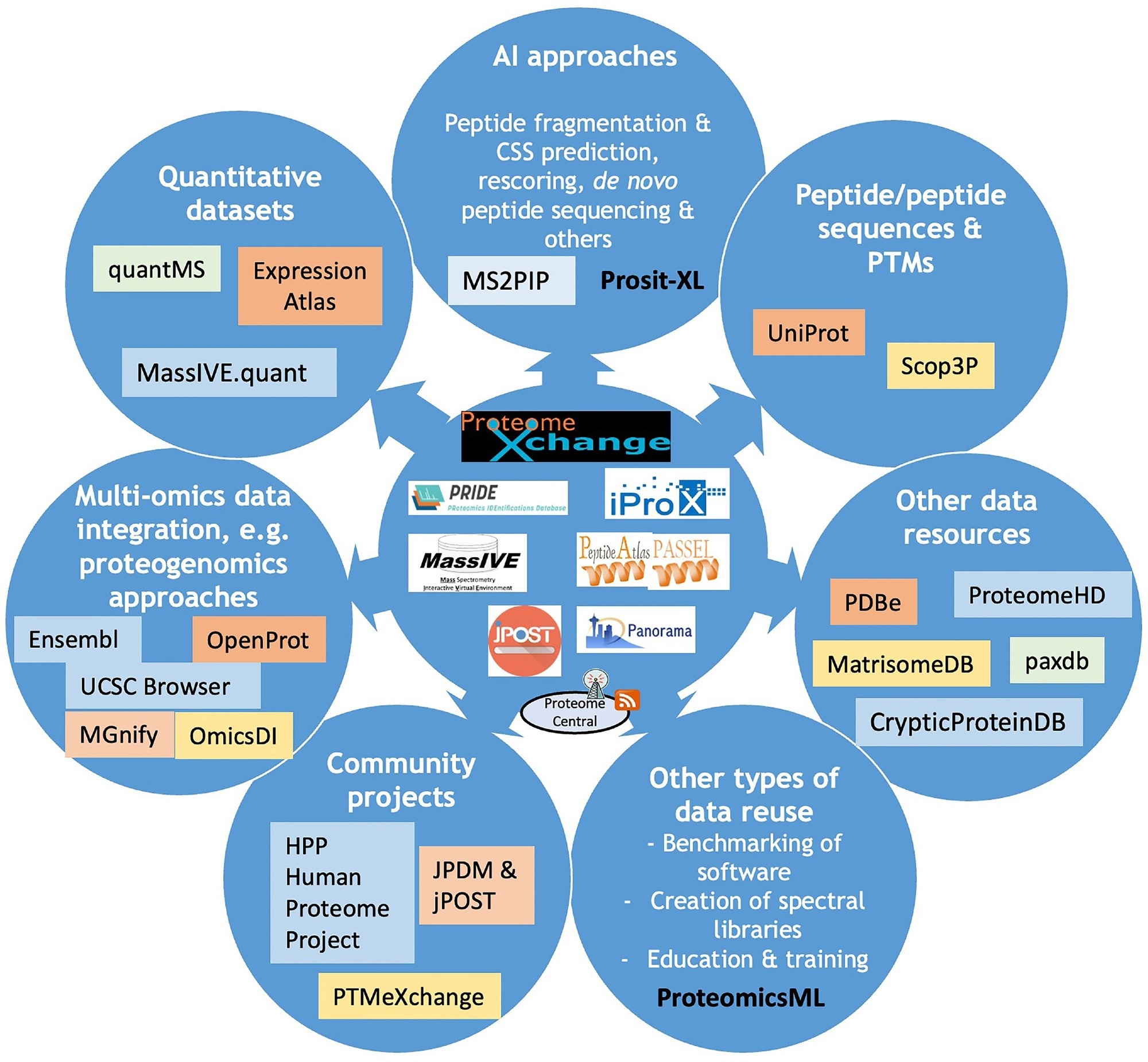
Overview figure including the current ProteomeXchange resources and the main efforts devoted to data reuse of public proteomics datasets. Different types of data reuse are listed and for each of them, the corresponding tools and/or data resources where these data can be accessed are indicated.
Most of the submissions were from the PRIDE repository (77%), followed by iProX (11%), MassIVE (7.4%), jPOST (3.8%), and very small amounts from Panorama Public and PeptideAtlas. Over 80 countries contributed to these public proteomics resources, indicating that proteomics use in biomedical research is widespread globally.
ProteomeXchange resources increasingly support standardized formats and richer metadata to enhance interoperability across datasets. The PSI-developed formats and SDRF-Proteomics enhanced the metadata from the datasets by improving their quality, reproducibility, and value. The overall use of USIs facilitated the access to and visualization of individual spectra in multiple different data repositories. This enhanced the transparency and validation of experimental results.
Data reuse activities also increased across the consortium. Public datasets were reanalyzed to obtain new biological insights, such as validating protein sequences and identifying post-translational modifications. The integration with UniProt Knowledge Base (UniProtKB) helped map more than 93% of the human proteome, showing the power of data analytics.
Quantitative proteomics resources such as MassIVE.quant and quantms enabled reproducible large-scale analyses. Additionally, multi-omics integration through resources like Omics Discovery Index (OmicsDI) and MGnify helped integrate proteomics, genomics, and transcriptomics datasets.
Artificial intelligence and machine learning applications were increasingly supported by the availability of high-quality datasets. Tools such as MassIVE-Knowledge-Base (MassIVE-KB) and ProteomicsML enabled the development of predictive models for peptide identification, fragmentation, and protein quantification. These advances are transforming proteomics into a data-driven field with potential future applications in precision medicine.
There are still many challenges that exist in this field of research. Due to privacy regulations like the General Data Protection Regulation (GDPR) and the Health Insurance Portability and Accountability Act (HIPAA), more controlled-access systems and repository capabilities are needed for human data. Additionally, new technologies have emerged that use proteomics as a primary measurement method and do not depend on mass spectrometry, including affinity proteomics platforms such as SomaLogic and Olink assays. This will lead to new research methodologies; therefore, researchers may need additional resources.
Future Directions for FAIR Proteomics Infrastructure
The ProteomeXchange Consortium has created an innovative, collaborative environment for the global sharing of proteomics data, aligned with FAIR principles. The introduction of standardized formats, increased scalability, and the provision of cutting-edge analytical tools have facilitated the broad reuse of existing data to advance innovations in biology and medicine. However, future progress depends on solving data privacy, scalability, and emerging technologies.
There is an ongoing need for innovation and collaboration to maintain broad accessibility and support the continued reliability and impact of proteomics data in advancing scientific discovery and enabling wider bioinformatics reuse.
Source:
Journal reference:
- Deutsch, E. W., Bandeira, N., Perez-Riverol, Y., Sharma, V., Carver, J. J., Mendoza, L., Kundu, D. J., Bandla, C., Kamatchinathan, S., Hewapathirana, S., Sun, Z., Kawano, S., Okuda, S., Connolly, B., MacLean, B., MacCoss, M. J., Chen, T., Zhu, Y., Ishihama, Y., & Vizcaíno, J. A. (2026). The ProteomeXchange consortium in 2026: Making proteomics data FAIR. Nucleic Acids Research. 54(D1). D459–D469. DOI: 10.1093/nar/gkaf1146, https://academic.oup.com/nar/article/54/D1/D459/8315797