
OpenAI finally launched its frontier o3-mini model in response to China’s DeepSeek R1 reasoning model this weekend. The o3-series of models were announced in December last year. OpenAI did not waste any time and launched o3-mini and o3-mini-high to keep its lead in the AI race. So, we were curious about all the things ChatGPT o3-mini does better than other AI models, and well, we tested it out. We have tested its coding prowess and discussed various benchmarks rigorously. On that note, let’s dive in.
1. Exceptional Coding Performance
OpenAI says o3-mini delivers exceptional performance in coding tasks while keeping the cost low and maintaining great speed. Prior to the o3-mini model, Anthropic’s Claude 3.5 Sonnet was the go-to model for programming queries. But that’s changing with the o3-mini release, specifically with the o3-mini-high model available to ChatGPT Plus and Pro users.
I tested the o3-mini-high model and asked it to create a Python snake game where multiple autonomous snakes compete with each other. The o3-mini-high model thought for 1 minute and 10 seconds and generated the Python code in one shot.
I executed the code, and it ran smoothly without any issues. It was fun to watch autonomous snakes make their moves, and it was absolutely precise, just like humans play!


After all, the o3-mini-high model has achieved an Elo score of 2,130 on the Codeforces competitive programming platform. This puts the o3-mini-high model among the top 2500 programmers in the world. Apart from that, in the SWE-bench Verified benchmark that evaluates capabilities in solving real-world software issues, o3-mini-high achieved 49.3% accuracy, which is even higher than the larger o1 model (48.9%).
So for AI coding assistance, I think the o3-mini-high model will offer you the best performance until the full o3 model comes out, which Sam Altman says is coming in a few weeks.
2. Ask Challenging Math Problems
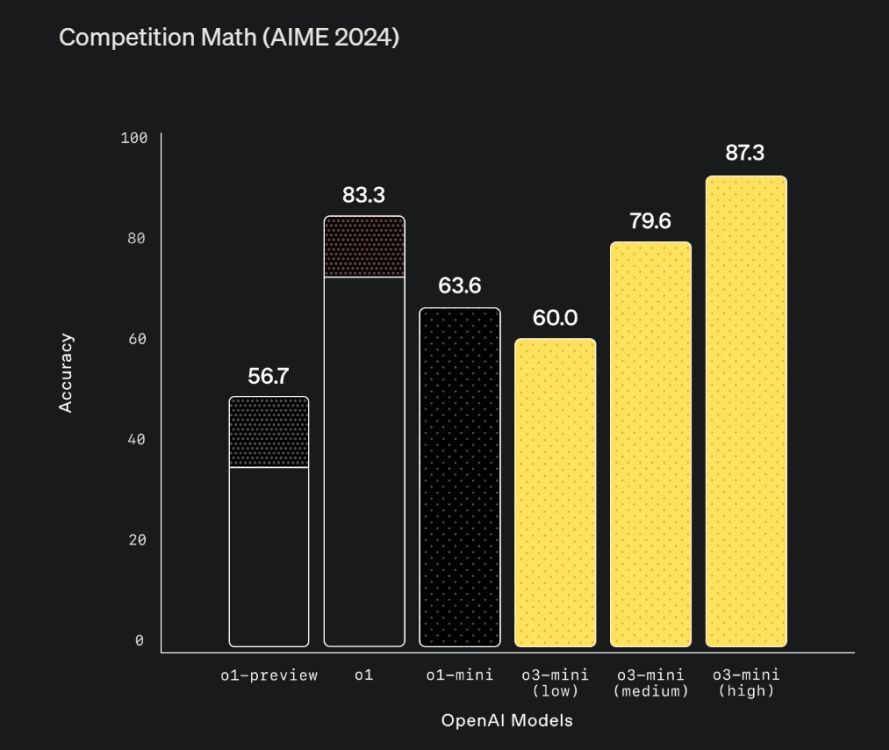
Apart from coding, math is another discipline where the o3-mini model outperforms other AI models. In the prestigious 2024 American Invitational Mathematics Examination (AIME), which has questions from number theory, probability, algebra, geometry, etc., the o3-mini-high achieved an impressive 87.3% again, higher than the full o1 model.

In the rigorous FrontierMath benchmark which features expert-level math problems from leading mathematicians, Fields Medalists, and professors from around the world, o3-mini-high achieved 20% after eight attempts. Even in a single attempt, it scored 9.2%, which is still significant.
To put this into perspective, renowned mathematician Terence Tao has described the problems in FrontierMath benchmark as “extremely challenging”. It can take hours and days to solve them, even for expert mathematicians. Other ChatGPT alternatives have only managed to achieve only 2% in this benchmark.
3. Your PhD-level Science Expert
The o3-mini-high model also excels at PhD-level science questions and beats other AI models by a significant margin. GPQA Diamond is an advanced benchmark that evaluates the capabilities of AI models in specialized scientific domains. It consists of advanced questions from the fields of biology, physics, and chemistry.

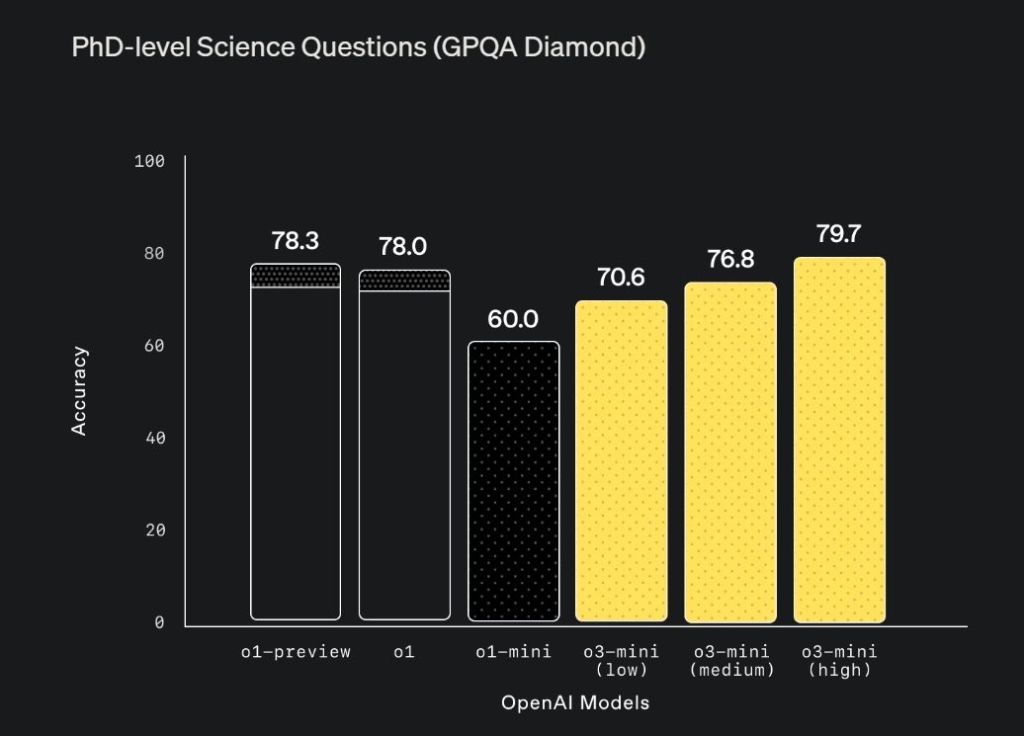
In the GPQA Diamond benchmark, o3-mini-high scored a remarkable 79.7%, outranking the larger o1 model (78.0%). For comparison, Google’s latest Gemini 2.0 Flash Thinking (Exp-01-21) reasoning model could manage 73.3%. Even the new Claude 3.5 Sonnet model stands at 65% in the GPQA Diamond benchmark.
It goes on to show that OpenAI’s smaller o3-mini model when given more time and compute to think, can outperform other AI models at expert-level science questions.
4. General Knowledge
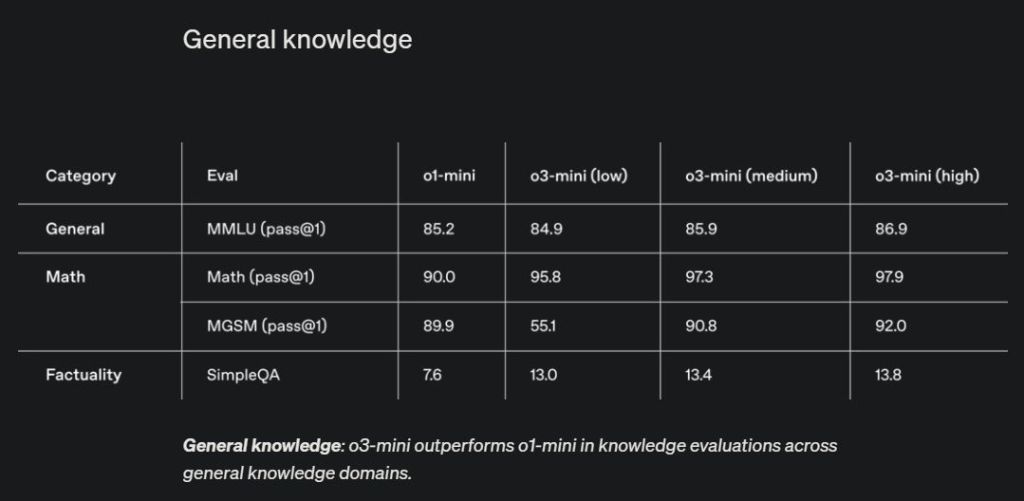
Across general knowledge domains, it’s expected that o3-mini wouldn’t beat larger models as it’s smaller and specialized for coding, math, and science. However, despite its smaller size, it comes very close to matching larger models. In the MMLU benchmark that assesses the performance of AI models across a wide variety of subjects, o3-mini-high scores 86.9% whereas OpenAI’s own GPT-4o model gets 88.7%.

That said, the upcoming larger o3 model would easily beat all AI models out there across general knowledge domains. I say this because the full o1 model already achieved 92.3% on the MMLU benchmark. Now, we need to wait for the full o3 model that might saturate the benchmark entirely.
5. o3-mini with Web Search

The knowledge cutoff of o3-mini is October 2023 which is quite old at this point. However, OpenAI has added web search support for the o3-mini model, allowing the reasoning model to extract the latest information from the web and perform advanced reasoning. DeepSeek R1 also does this, but no other reasoning model lets you access the web for further reasoning.
So these are some of the advanced capabilities of the o3-mini model. While free ChatGPT users can also access o3-mini, the reasoning effort is set to “medium” which uses less compute.
I would recommend paying for the ChatGPT Plus subscription, which costs $20/month, to unlock the powerful ‘o3-mini-high’ model. For professional coders, researchers, and undergraduate STEM students, the o3-mini-high model can be highly beneficial.


Source link
-

-

-

-

-

-

-

-







