

How APIs Work: The Hidden Infrastructure Behind Modern Apps
A beginner-friendly guide to how APIs connect software, power modern applications, and enable everything from payments and messaging to AI-powered automations.
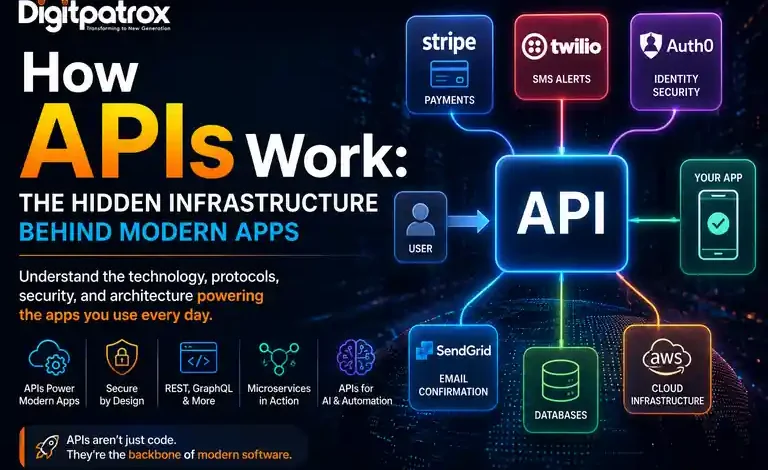
The most successful piece of software engineering is the one your user never notices.
When you book a ride on an app, check the morning weather, or authenticate a login with a single tap, you aren’t interacting with a single monolithic program. You are interacting with a distributed ecosystem of completely independent systems, stitched together in real time.
APIs (Application Programming Interfaces) are the digital glue of modern software architecture. They have quietly shifted the entire industry away from building everything from scratch and toward an assembly-based economy. Modern software is rarely built from the ground up; it is assembled from specialized APIs.
Executive Reality Check
-
Software is assembly, not raw creation: Modern application development relies more on coordinating third-party APIs than writing core baseline logic.
-
The network is your largest security boundary: Shifting logic to APIs means your data security is heavily dependent on how well you manage authorization protocols, transport encryption, and access keys.
-
API dependencies introduce system fragility: When you rely on external APIs for core functions like payments or mapping, their downtime instantly becomes your application’s downtime.
-
Latency compounds across endpoints: A single user action can trigger a cascade of internal API requests. If one endpoint slows down, the entire user experience bottlenecks.
-
Vendor lock-in creates architectural inertia: Once an application depends deeply on specialized external workflows for identity or billing, switching providers becomes prohibitively expensive.
The Short Answer
An API is a standardized code interface that allows completely different software applications to securely communicate and exchange data automatically. Instead of building complex, specialized features from scratch—such as global credit card processing networks or text message delivery platforms—developers use APIs to plug those pre-built services directly into their apps. This modular approach allows small engineering teams to deploy complex, global application infrastructure in a fraction of the traditional development time.
The Evolution of Software: Monoliths vs. API-Driven Assemblies
To appreciate how deeply APIs dictate modern web development, it helps to look at how much the baseline architecture has changed over the last two decades.
Traditional Monolithic App
User
↓
The Monolith Application
├── Local Database
├── Custom Payment Logic
├── Custom Notification Engine
└── Internal Server Code
In the monolithic era of software engineering, an application was a single, massive codebase. If you wanted to build an e-commerce platform, your internal team had to write the web interface, build the database architecture, construct a secure vault to store raw credit card numbers, and maintain a local server cluster to send transactional notification emails. This structural layout made applications incredibly slow to build and highly brittle to scale.
Modern API-First Mesh
User
↓
Application Coordination Layer
↓
API Gateway
├── Stripe API (Payments)
├── Twilio API (SMS Alerts)
└── Auth0 API (Identity Security)
Modern application design avoids this structural repetition entirely. Today, an application acts as a coordination layer. When a user checks out on a modern storefront, the app doesn’t process the credit card natively; it hands the data off securely to a dedicated payment API like Stripe. To send a shipping text message, it forwards a payload to a communications API like Twilio.
The Single Biggest Shift
A monolithic application scales by building larger local servers. An API-driven application scales by distributing specialized tasks to the most reliable external network.
What Happens When You Tap “Pay Now”
To see this modular assembly in motion, consider what happens under the hood during a standard check-out sequence on a food delivery app. To the user, it feels like a single, seamless interaction. On the backend, it triggers a massive distributed chain reaction.
[ User Taps "Pay Now" ]
│
▼
[ App Coordination Layer ]
│
├─── (1) Check Identity ──────────> [ Auth0 API ]
├─── (2) Process Credit Card ─────> [ Stripe API ] ──> [ Bank / Fraud Networks ]
├─── (3) Trigger Confirmation ───> [ SendGrid API ] (Email)
└─── (4) Alert Delivery Driver ──> [ Twilio API ] (SMS)
One simple tap on your phone screen can instantly execute:
-
Five distinct API calls cross-referencing security headers.
-
Three separate external infrastructure vendors running independent cloud architectures.
-
Multiple databases and regions syncing financial and logistical ledger balances simultaneously.
The entire process finishes within a few hundred milliseconds, and the user never notices the underlying choreography.
The Technology Layer: Protocols, Contracts, and Data Payloads
At its core, an API functions as a strict legal contract between two separate computer systems. The contract states: “If you send me data in exactly this format, I promise to return a response in exactly that format.”
To enforce these contracts cleanly at scale, the software industry relies heavily on standardized design protocols:
1. REST (Representational State Transfer)
REST is the dominant architecture for standard web applications. It relies entirely on standard HTTP communication methods. You use REST APIs constantly every day, even if you never see them.
Imagine opening a food delivery app on your phone:
-
When you refresh the restaurant list, your phone calls:
GET /restaurants -
When you place your order, your phone calls:
POST /orders -
When you cancel an order, your phone calls:
DELETE /orders/123
REST APIs pass data back and forth using JSON (JavaScript Object Notation), a lightweight, human-readable text format that structures information into clear key-value pairs:
{
"transaction_id": "tx_99823",
"amount_usd": 45.00,
"status": "settled"
}
2. GraphQL
GraphQL is a query language developed to solve specific data efficiency problems. While a REST API forces your app to download a fixed package of data every time you call an endpoint, GraphQL allows an application to request only the specific fields it needs for a specific screen, vastly reducing mobile network traffic overhead.
3. gRPC and WebSockets
These are specialized, high-speed protocols designed for real-time systems. WebSockets maintain a persistent, open line of bidirectional communication—essential for live chat apps or financial stock tickers—while gRPC uses compressed binary payloads to pass data between internal backend systems with near-zero network delay.
Pre-Request Middleware: The Security and Performance Boundary
Because API endpoints are exposed to the public internet, they are prime targets for malicious actors, automated scraping bots, and brute-force attacks. Before an incoming API request ever reaches core database resources, it must pass through an extensive preprocessing boundary.
Incoming API Request
↓
API Gateway ──── (Validates OAuth / JWT / API Keys)
↓
Rate Limiter ──── (Triggers HTTP 429 Error if limit exceeded)
↓
Microservice Logic
Depending on the specific application platform, this entry gate handles critical operational safety tasks sequentially:
-
Authentication Layer: The system inspects incoming security headers to verify identity, validating cryptographic signatures, API keys, or JSON Web Tokens (JWT). For a closer look at the underlying protocols keeping these secure, read our analysis on what is oauth and why ai agents depend on it.
-
Rate Limiting: To prevent an accidental code loop or a malicious Denial of Service (DoS) attack from crashing servers, the gateway tracks the incoming IP address. If a user tries to hit the endpoint more than a set threshold in a single second, the engine blocks the request and returns an explicit
HTTP 429 Too Many Requestserror. -
Telemetry and Logging: Every incoming request leaves a metric footprint tracking latency, source region, and execution error rates. Software teams monitor these logs closely to ensure their integrations remain stable. To learn how engineering teams track these distributed data steps across multiple distinct systems, explore our guide on ai observability explained.
The Shifting Landscape: APIs Are Becoming Machine Interfaces
The modern API economy is expanding rapidly beyond basic data sharing between human interfaces. Humans are no longer the only API consumers. With the introduction of large language models and autonomous software platforms, APIs are transitioning into actionable nervous systems for automated software tools.
Modern AI systems increasingly use APIs to take direct actions:
-
Reading and triaging incoming emails
-
Updating customer records inside enterprise CRMs
-
Creating deployment tickets inside engineering repositories
-
Searching across isolated relational databases
This allows AI applications to move beyond simply answering text prompts and begin taking actions in real-world systems. Emerging technical standards aim to make it much easier for AI software engines to dynamically interact with these third-party environments. Engineers looking to maximize speed during these integration builds often evaluate cutting-edge IDE setups; see our direct comparison on cursor vs windsurf vs claude code to see which tooling matches your system assembly style.
For a hands-on technical walkthrough on connecting these intelligent routing blocks into functional business loops, see our complete tutorial on how to build an ai agent with n8n and mcp.
The 6-Month Reality Check: What Breaks Post-Deployment
Building an application with APIs feels incredibly fast during initial development. However, maintaining that ecosystem across months of sustained production traffic reveals specific architectural friction points:
-
Silent Upstream Failures: Third-party APIs don’t always crash completely. A service can experience localized regional routing delays where its endpoint remains live but takes 12 seconds to respond instead of 100 milliseconds. Your provider’s public status page will display a bright green checkbox reading “All Systems Operational” because the server isn’t down—it’s just slow enough to break everything. If your codebase doesn’t enforce strict connection timeouts, your entire application queue can back up, locking up local resources while waiting indefinitely.
-
The Cascading Error Trap: In assembled software layouts, endpoints frequently rely on other endpoints. If a downstream dependency throws an unhandled error, that failure can propagate back up the execution line, corrupting data mappings and causing completely unrelated parts of your user interface to fail unexpectedly.
-
Hidden Usage Cost Creep: Most commercial APIs use volume-based pricing models. A sudden surge in user traffic or a malfunctioning code loop that continuously polls an external server can drive up API transaction volumes, transforming a low-cost utility service into a massive operational bill over a single weekend. To better evaluate the hidden structural components of running modern backend processes at scale, review our core architecture index on the ai infrastructure stack 2026.
Final Sourcing Matrix
Choosing how to balance your internal software creation against third-party API dependencies requires a clear understanding of long-term operational trade-offs.
[ Component Sourcing Strategy ]
│
┌─────────────────────────┴─────────────────────────┐
▼ ▼
[ External Third-Party APIs ] [ Native Custom Internal Builds ]
- Instant Market Rollout - Long Development Cycles
- Zero Local Maintenance - Permanent Maintenance Overhead
- Exposure to Vendor Risk - Total Control of Data & Latency
Component Sourcing Comparison
| Evaluation Dimension | External Third-Party APIs (Stripe, Twilio, Google Maps) | Custom Internal Code (Building Features From Scratch) |
| Best Use Case | Commodities or complex global features that are non-core to your unique value proposition. | Core business intellectual property, specialized data operations, or ultra-low-latency workflows. |
| Worst Use Case | High-volume workflows where transaction fees completely erode product margins. | Standard utilities (like email delivery) that have already been optimized globally by dedicated platforms. |
| Maintenance Burden | Low; limited entirely to managing version updates and upstream endpoint deprecations. | Extremely high; requires full-time development teams to fix bugs, optimize performance, and scale database schemas. |
| Control & Security | Restricted; you are heavily influenced by the vendor’s data handling policies, pricing models, and uptime guarantees. | Absolute; your internal engineering group defines all access rules, security configurations, and data residency boundaries. |
For a deeper structural evaluation of how these workflow engineering frameworks stack up against each other under enterprise automation conditions, see our analysis of zapier vs make vs n8n.
Summary: The Interconnected Architecture Paradigm
Twenty years of software culture trained the industry to measure a platform’s capability by the absolute size of its local codebase. APIs have fundamentally changed that framework.
Today, the strength of an application isn’t measured by how much code it owns locally, but by how effectively it coordinates a distributed global network of specialized microservices.
The dominant engineering priorities have transformed:
-
System Integration has replaced raw feature development as the primary velocity driver.
-
API Security & Token Validation have replaced local server firewalls as the critical defensive perimeter.
-
Asynchronous Error Handling has replaced simple try/catch blocks as the metric that ensures application uptime.
The ultimate challenge of modern software development isn’t building the supercomputer from scratch. It is constructing a reliable, clean, and secure routing layer that moves data smoothly across dozens of independent global platforms—ensuring the collective execution feels entirely instantaneous and invisible to the end user.