

The Best AI Tools for Small Businesses in 2026
How SMBs Are Reducing Operational Friction with Reliable AI Workflows, Smarter Automation, and Human-Centered Systems

The Best AI Tools for Small Businesses in 2026: Building Systems That Actually Last
Small businesses don’t have a shortage of AI tools in 2026. They have a shortage of reliable systems.
Most software roundups focus on what AI tools can do on day one. Very few explain what happens by month six, when workflows break, software integrations drift, and nobody remembers how the pieces were connected in the first place.
These tools can genuinely transform how a small team operates, but only if you understand where complexity enters the system. Instead of chasing the hype of autonomous AI employees, the most successful small businesses are building quiet, highly reliable configurations that scale without requiring an in-house developer to maintain them.
Here is how to navigate the AI landscape in 2026, avoid the hidden traps, and build an operational stack that actually works.
The Integration Tax (Why Most SMB AI Stacks Fail)
Before choosing a specific tool, it is crucial to understand the hidden cost of AI adoption. This is the Integration Tax-the cumulative time and operational overhead required to monitor, patch, and debug AI connections once they are deployed into production.
Over time, AI systems suffer from Automation Debt. Old data piles up inside your prompts, cloud applications silently change their data fields, and automated workflows break without warning.
Consider a real example from an e-commerce brand: they built a multi-step automation to parse customer custom orders from emails and port them directly into their shipping portal. It worked perfectly for months. Then, the shipping provider pushed a minor software update that altered their address schema. Because there was no error-handling protocol in place, the automation silently failed for 11 days, misrouting over 140 orders before anyone noticed the discrepancy.
Setting up a modern AI utility takes ten minutes. Maintaining it when your business data changes takes continuous discipline.
The goal is not to automate everything. It is to automate the specific bottlenecks that repeatedly drain your team’s time.
The Real ROI of AI for Small Businesses
The biggest benefit of AI is rarely replacing employees. It is reducing coordination overhead. Small businesses gain massive leverage when employees spend less time moving information between systems and more time making actual decisions.
The Hidden Drag of Coordination Overhead
Without AI: [Employee] ──> Read Email ──> Open CRM ──> Copy Data ──> Ping Team ──> Create Invoice
With AI: [Employee] ──> [ AI Automated Logic & Draft Generation ] ──> [Human One-Click Approval]
The most successful small businesses in 2026 are building quieter, more efficient operations by targeting basic friction:
-
Fewer internal status update meetings.
-
Less manual data entry across disconnected web apps.
-
Faster internal document retrieval.
-
Cleaner client onboarding sequences.
-
Quicker, context-aware responses to customers.
Most SMB AI projects don’t fail because an LLM gave a weird answer. They fail because nobody maintained the underlying workflow six months later. The companies getting the highest financial return from AI are usually not the loudest about it. They are simply using deterministic software to remove friction from everyday work.
Foundational Intelligence: The Brains of the Operation
What Matters Most: In 2026, raw foundational models capable of handling massive documents have largely replaced specialized AI writing platforms. Instead of paying a premium for a dedicated niche app, your choice primarily comes down to how a model handles large sets of information.
The battle for the small business desktop is largely centered on Claude vs ChatGPT vs Gemini vs Grok. For core operational work-analyzing complex financial spreadsheets, drafting standard operating procedures, and parsing long PDFs-Claude (specifically the 3.5 Sonnet tier) remains the operational benchmark.
Claude outperforms competitor models in production because of its structural reliability; it maintains strict adherence to formatting constraints and avoids AI hallucinations when extracting raw data from deep within page 40 of an unformatted contract.
ChatGPT remains the superior choice if your team relies heavily on native mobile access, advanced real-time voice modes, or building simple, ring-fenced interfaces (Custom GPTs) for quick, non-technical daily tasks.
What Success Looks Like: A five-person marketing agency does not need a fully autonomous AI employee. It needs a reliable workflow where Claude summarizes client transcripts, drafts weekly status reports, and flags overdue approvals. It is a simple, high-impact use case that requires zero maintenance.
Workflow Automation: Tying Your Business Together
Automation used to mean simple triggers that moved basic text from one app to another. Today, the biggest shift is moving to logic-based routing. The best AI automation tools evaluate incoming data, categorize it, and decide whether a human needs to step in to make a final call.
When evaluating Zapier vs Make vs n8n, the decision is a balance between ease of use and long-term costs. Zapier remains the most intuitive platform. You can set it up in minutes, but it becomes noticeably expensive once your workflows start running hundreds of multi-step tasks every day.
Make is excellent for growing teams because it offers far more visual flexibility than Zapier at a significantly lower cost. The main tradeoff is visual complexity. One operations agency recently discovered this when their main routing scenario reached 42 connected modules. A single webhook timeout caused an unhandled logic loop that drained their entire monthly task allocation in a single afternoon. Once a workflow grows past 15 modules, debugging becomes a major headache unless your team documents the logic carefully.
Internal Knowledge & Search
Most businesses do not have a tooling problem. They have an information retrieval problem. Modern AI search tools can now retrieve, read, and summarize information across your company files almost instantly using an approach called what is Agentic RAG. It eliminates the need to dig through endless Slack channels by turning company files into an instant internal Q&A system.
To make an internal AI search tool work across platforms like Notion AI or Glean, you must practice strict Retrieval Hygiene.
Here is the most important rule of implementing internal AI search: The AI does not know which file is accurate; it only knows which file is mathematically relevant to the search query.
We recently reviewed an operations team that found three completely different versions of a “Refund Policy” active within their shared drive. The AI search tool pulled information from a deprecated 2022 document simply because the phrasing in that older file matched the employee’s query more closely. Your AI search tool will only ever be as smart as your underlying folder hygiene.
Web & Code: Building Without Developers
Two years ago, building a custom internal tool usually meant hiring a freelancer. In 2026, many small business owners are building lightweight dashboards and automations themselves using AI coding tools.
Tools like Cursor vs Windsurf vs Claude Code look like standard code editors, but they function like a patient senior developer guiding you. If you need a specific client portal or an inventory calculator that standard software does not quite handle, you can use Cursor to build it yourself.
The main tradeoff here is scope. These tools are phenomenal for building single-purpose internal tools. Just remember that if an underlying web library updates a year from now, you will need to open the tool back up and ask the AI to help you fix the resulting error.
What Actually Scales
When building out your small business stack, the configurations that last are the ones designed with human reality in mind.
Prioritize Deterministic Workflows Over Autonomous Agents
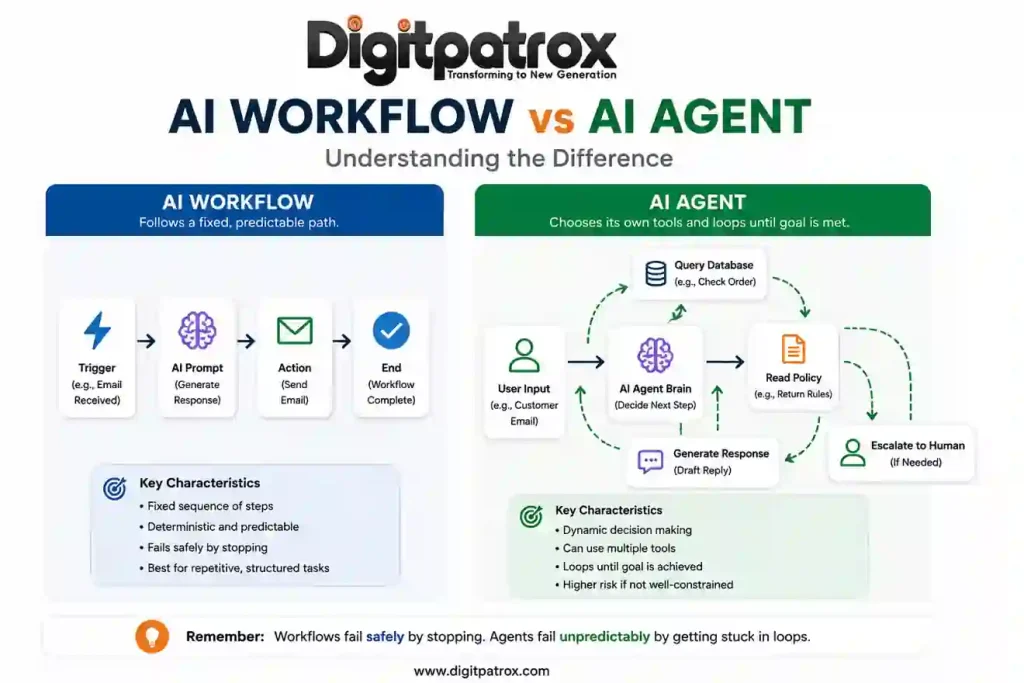
Understanding the difference between AI workflows vs AI agents is a critical operational distinction. A workflow follows exact, predictable, predefined rules. An agent makes its own dynamic decisions about which tools or approaches to use.
For 95 percent of small business operations, you want predictable rules with AI elements added just to read, evaluate, or format text. A reliable boring workflow is usually more valuable than an impressive autonomous agent.
Build an Explicit Human Approval Layer
The goal is not to remove humans from the process. It is to remove repetitive friction from the process. Never let an AI send a final invoice, publish code, or dispatch a mass marketing email without a human clicking approve. Using AI to generate the draft saves 90 percent of the time; keeping the human in the loop prevents 100 percent of the catastrophic errors.
Signs Your SMB Is Over-Automating
-
The Maintenance Deficit: You spend more hours updating API mappings and debugging webhook errors than the automation saves you in manual work.
-
Logic Opacity: Your team cannot explain how data moves from your CRM to your accounting software because the logic is hidden inside a giant, undocumented cloud automation.
-
Context Collapse: Customer interactions feel rigid or disconnected because an AI is handling communications that require genuine personal nuance or localized exceptions.
The 2026 Decision Matrix
Technical and Operational Cost Breakdown
| Team Profile | Recommended Core Stack | Primary Cost Driver | The Operational Tradeoff |
| Non-Technical, Lean Teams (1 to 5 people) | ChatGPT Plus, Zapier, Notion AI | Subscription fees & task scaling: Zapier plans scale aggressively based on volume. | Zapier is excellent early on, but costs increase quickly once your automations handle daily operational traffic. |
| Operationally Heavy Teams (Agencies, E-commerce) | Claude Sonnet, Make, Perplexity | Maintenance overhead: Time spent auditing branching visual scenarios. | Make workflows remain affordable at scale, but large visual automations become difficult to troubleshoot without clear documentation. |
| Tech-Adjacent Teams (Comfortable with APIs) | Cursor, n8n, Custom API scripts | DevOps & monitoring infrastructure: Self-hosting or webhook management costs. | A single API version change can silently break a production workflow if nobody is actively monitoring webhook errors. |
Financial Efficiency at Scale
| Integration Layer | Approx. Monthly Cost | Main Risk Profile | Mitigation Strategy |
| Zapier | High ($$$) | Task Inflation: Multi-step zaps run up execution bills instantly. | Reserve for low-volume, critical system handoffs. |
| Make | Medium ($$) | Workflow Complexity: Heavy branching makes errors hard to spot. | Keep scenarios under 15 modules and document paths. |
| n8n | Low ($) | Maintenance Burden: Self-hosting requires active DevOps time. | Use the managed cloud tier if you lack in-house server talent. |
FAQ
Do I need a custom AI agent for my small business?
Probably not. Most small businesses benefit far more from reliable, step-by-step automations than from fully autonomous AI agents. Agents require highly structured, predictable environments to operate safely. If your business processes change frequently, an autonomous agent will struggle to keep up.
Are AI meeting assistants worth the privacy risk?
For most teams, yes. The best AI meeting assistants in 2026 like Fathom or Fireflies save hours every week in note-taking and follow-ups. The privacy risk is manageable if you use top-tier tools with SOC2 compliance, but it is best practice to pause them during highly sensitive financial or HR discussions.
Should I pay for both ChatGPT and Claude?
It is usually best to pick one to avoid fragmenting your team’s workflow. If you analyze heavy data, write long-form copy, or deal with massive PDFs, Claude is currently the stronger choice. If your team values mobile access, voice interaction, and quick conversational brainstorming, lean toward ChatGPT.
Why do my AI search tools give me wrong answers about my own company?
This is often caused by retrieval poisoning. If you have outdated Standard Operating Procedures (SOPs) mixed in with current ones, the AI struggles to determine the truth. Archiving old documents will immediately improve your AI’s accuracy.
Is Prompt Engineering still a thing in 2026?
Not in the rigid way it was in 2023. You no longer need bizarre formatting tricks to get good results. However, providing good context-giving the AI exactly the right background information, constraints, and examples-remains a highly valuable skill for any team.
Summary: Building for Resilience
The small businesses winning with AI in 2026 are not building completely autonomous companies. They are building robust operational configurations that fail gracefully, remain understandable to the humans running them, and reduce day-to-day friction without stripping away personal accountability. Focus on data cleanliness, keep your automated workflows simple, and always maintain an explicit approval layer where it matters most.